import ospath = "C:\Pycharm"print(os.listdir(path))# 方法一:(不使用os.walk)def print_directory_contents(sPath): import os for sChild in os.listdir(sPath): sChildPath = os.path.join(sPath, sChild) if os.path.isdir(sChildPath): print_directory_contents(sChildPath) else: print(sChildPath) # 方法二:(使用os.walk)def print_directory_contents(sPath): import os for root, _, filenames in os.walk(sPath): for filename in filenames: print(os.path.abspath(os.path.join(root, filename)))print_directory_contents('已知路径')sPath-- 是你所要便利的目录的地址, 返回的是一个三元组(root,dirs,files)。 root 所指的是当前正在遍历的这个文件夹的本身的地址 _ 是一个 list ,内容是该文件夹中所有的目录的名字(不包括子目录) filenames 同样是 list , 内容是该文件夹中所有的文件(不包括子目录)
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutorhttp://www.cnblogs.com/haiyan123/p/7461294.htmlhttp://www.cnblogs.com/wanghzh/p/5607067.html
1.索引: B+/哈希索引 =》 查找速度快;更新速度慢 单列: - 普通索引:加速查找 - 唯一索引: 加速查找 + 约束:不能重复 - 主键: 加速查找 + 约束:不能重复 + 不能为空 多列: - 联合索引 - 联合唯一索引 PS:遵循最左前缀的规则 其他词语: - 索引合并,利用多个单例索引查询; - 覆盖索引,在索引表中就能将想要的数据查询到; 2.创建了索引,应该如何命中索引? 那种情况下,创建了无法命中索引? - like '%xx' select * from tb1 where name like '%cn'; - 使用函数 select * from tb1 where reverse(name) = 'wupeiqi'; - or select * from tb1 where nid = 1 or email = 'seven@live.com'; 特别的:当or条件中有未建立索引的列才失效,以下会走索引 select * from tb1 where nid = 1 or name = 'seven'; select * from tb1 where nid = 1 or email = 'seven@live.com' and name = 'alex' - 类型不一致 如果列是字符串类型,传入条件是必须用引号引起来,不然... select * from tb1 where name = 999; - != select * from tb1 where name != 'alex' 特别的:如果是主键,则还是会走索引 select * from tb1 where nid != 123 - > select * from tb1 where name > 'alex' 特别的:如果是主键或索引是整数类型,则还是会走索引 select * from tb1 where nid > 123 select * from tb1 where num > 123 - order by select email from tb1 order by name desc; 当根据索引排序时候,选择的映射如果不是索引,则不走索引 特别的:如果对主键排序,则还是走索引: select * from tb1 order by nid desc;3.组合索引最左前缀 如果组合索引为:(name,email) name and email -- 使用索引 name -- 使用索引 email -- 不使用索引
问:查询页数越大效率越低,如何优化?select * form tb limit 10 offset 0select * form tb limit 10 offset 10select * form tb limit 10 offset 20select * form tb limit 10 offset 30...select * form tb limit 10 offset 3000000 答案一: 先查主键,在分页。 select * from tb where id in ( select id from tb where limit 10 offset 30 )答案二: 按照也无需求是否可以设置只让用户看200页 答案三: 记录当前页 数据ID最大值和最小值 在翻页时,根据条件先进行筛选;筛选完毕之后,再根据limit offset 查询。 select * from (select * from tb where id > 22222222) as B limit 10 offset 0 如果用户自己修改页码,也可能导致慢;此时对url种的页码进行加密(rest framework )
- 装饰器from django.views import Viewfrom django.utils.decorators import method_decoratordef auth(func): def inner(*args,**kwargs): return func(*args,**kwargs) return innerclass UserView(View): @method_decorator(auth) def get(self,request,*args,**kwargs): return HttpResponse('...')- csrf的装饰器要加到dispath from django.views import View from django.utils.decorators import method_decorator from django.views.decorators.csrf import csrf_exempt,csrf_protect class UserView(View): @method_decorator(csrf_exempt) def dispatch(self, request, *args, **kwargs): return HttpResponse('...') 或 from django.views import View from django.utils.decorators import method_decorator from django.views.decorators.csrf import csrf_exempt,csrf_protect @method_decorator(csrf_exempt,name='dispatch') class UserView(View): def dispatch(self, request, *args, **kwargs): return HttpResponse('...')
9.10 Django中form组件的作用
- 对用户请求的数据进行校验- 生成HTML标签PS: - form对象是一个可迭代对象。
9.11 如何在一个项目中使用多数据库
python manage.py makemigraionspython manage.py migrate app名称 --databse=配置文件数据名称的别名手动操作: models.UserType.objects.using('db1').create(title='普通用户') result = models.UserType.objects.all().using('default') 自动操作: 根目录下db_router.py : class Router1: def db_for_read(self, model, **hints): """ Attempts to read auth models go to auth_db. """ return 'db1' def db_for_write(self, model, **hints): """ Attempts to write auth models go to auth_db. """ return 'default' 配置: DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), }, 'db1': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db1.sqlite3'), }, } DATABASE_ROUTERS = ['db_router.Router1',] 使用: models.UserType.objects.create(title='VVIP') result = models.UserType.objects.all() print(result) 补充:粒度更细 class Router1: def db_for_read(self, model, **hints): """ Attempts to read auth models go to auth_db. """ if model._meta.model_name == 'usertype': return 'db1' else: return 'default' def db_for_write(self, model, **hints): """ Attempts to write auth models go to auth_db. """ return 'default'
9.12 如何在不同app中使用不同数据库
# 第一步: python manage.py makemigraions # 第二步: app01中的表在default数据库创建 python manage.py migrate app01 --database=default# 第三步: app02中的表在db1数据库创建 python manage.py migrate app02 --database=db1 # 手动操作: m1.UserType.objects.using('default').create(title='VVIP') m2.Users.objects.using('db1').create(name='VVIP',email='xxx')# 自动操作: 配置: class Router1: def db_for_read(self, model, **hints): """ Attempts to read auth models go to auth_db. """ if model._meta.app_label == 'app01': return 'default' else: return 'db1' def db_for_write(self, model, **hints): """ Attempts to write auth models go to auth_db. """ if model._meta.app_label == 'app01': return 'default' else: return 'db1' DATABASE_ROUTERS = ['db_router.Router1',] 使用: m1.UserType.objects.using('default').create(title='VVIP') m2.Users.objects.using('db1').create(name='VVIP',email='xxx')
9.13 如何在数据库迁移时进行读写约束
class Router1: def allow_migrate(self, db, app_label, model_name=None, **hints): """ All non-auth models end up in this pool. """ if db=='db1' and app_label == 'app02': return True elif db == 'default' and app_label == 'app01': return True else: return False # 如果返回None,那么表示交给后续的router,如果后续没有router,则相当于返回True def db_for_read(self, model, **hints): """ Attempts to read auth models go to auth_db. """ if model._meta.app_label == 'app01': return 'default' else: return 'db1' def db_for_write(self, model, **hints): """ Attempts to write auth models go to auth_db. """ if model._meta.app_label == 'app01': return 'default' else: return 'db1'
title = models.CharField(max_length=32) class UserInfo(models.Model): name = models.CharField(max_length=32) email = models.CharField(max_length=32) ut = models.ForeignKey(to='UserType') ut = models.ForeignKey(to='UserType') ut = models.ForeignKey(to='UserType') ut = models.ForeignKey(to='UserType') # 1次SQL # select * from userinfo objs = UserInfo.obejcts.all() for item in objs: print(item.name) # n+1次SQL # select * from userinfo objs = UserInfo.obejcts.all() for item in objs: # select * from usertype where id = item.id print(item.name,item.ut.title) 示例1: .select_related() # 1次SQL # select * from userinfo inner join usertype on userinfo.ut_id = usertype.id objs = UserInfo.obejcts.all().select_related('ut') for item in objs: print(item.name,item.ut.title) 示例2: .prefetch_related() # select * from userinfo where id <= 8 # 计算:[1,2] # select * from usertype where id in [1,2] objs = UserInfo.obejcts.filter(id__lte=8).prefetch_related('ut') for obj in objs: print(obj.name,obj.ut.title) 两个函数的作用都是减少查询次数 示例3: update()和对象.save()修改方式的性能PK 方式1 models.Book.objects.filter(id=1).update(price=3) 方式2 book_obj=models.Book.objects.get(id=1) book_obj.price=5 book_obj.save() 结论: update() 方式1修改数据的方式,比obj.save()性能好
11.9 取消外键约束用 db_constraint=False
无约束: class UserType(models.Model): title = models.CharField(max_length=32) class UserInfo(models.Model): name = models.CharField(max_length=32) email = models.CharField(max_length=32) # 无数据库约束,但可以进行链表 ut = models.ForeignKey(to='UserType',db_constraint=False)
11.10 QuerySet方法大全
################################################################## # PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET # ################################################################## def all(self) # 获取所有的数据对象 def filter(self, *args, **kwargs) # 条件查询 # 条件可以是:参数,字典,Q def exclude(self, *args, **kwargs) # 条件查询 # 条件可以是:参数,字典,Q def select_related(self, *fields) 性能相关:表之间进行join连表操作,一次性获取关联的数据。 model.tb.objects.all().select_related() model.tb.objects.all().select_related('外键字段') model.tb.objects.all().select_related('外键字段__外键字段') def prefetch_related(self, *lookups) 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 # 获取所有用户表 # 获取用户类型表where id in (用户表中的查到的所有用户ID) models.UserInfo.objects.prefetch_related('外键字段') from django.db.models import Count, Case, When, IntegerField Article.objects.annotate( numviews=Count(Case( When(readership__what_time__lt=treshold, then=1), output_field=CharField(), )) ) students = Student.objects.all().annotate(num_excused_absences=models.Sum( models.Case( models.When(absence__type='Excused', then=1), default=0, output_field=models.IntegerField() ))) def annotate(self, *args, **kwargs) # 用于实现聚合group by查询 from django.db.models import Count, Avg, Max, Min, Sum v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')) # SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1) # SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1) # SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 def distinct(self, *field_names) # 用于distinct去重 models.UserInfo.objects.values('nid').distinct() # select distinct nid from userinfo 注:只有在PostgreSQL中才能使用distinct进行去重 def order_by(self, *field_names) # 用于排序 models.UserInfo.objects.all().order_by('-id','age') def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # 构造额外的查询条件或者映射,如:子查询 Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,)) Entry.objects.extra(where=['headline=%s'], params=['Lennon']) Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"]) Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid']) def reverse(self): # 倒序 models.UserInfo.objects.all().order_by('-nid').reverse() # 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序 def defer(self, *fields): models.UserInfo.objects.defer('username','id') 或 models.UserInfo.objects.filter(...).defer('username','id') #映射中排除某列数据 def only(self, *fields): #仅取某个表中的数据 models.UserInfo.objects.only('username','id') 或 models.UserInfo.objects.filter(...).only('username','id') def using(self, alias): 指定使用的数据库,参数为别名(setting中的设置) ################################################## # PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS # ################################################## def raw(self, raw_query, params=None, translations=None, using=None): # 执行原生SQL models.UserInfo.objects.raw('select * from userinfo') # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名 models.UserInfo.objects.raw('select id as nid from 其他表') # 为原生SQL设置参数 models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,]) # 将获取的到列名转换为指定列名 name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'} Person.objects.raw('SELECT * FROM some_other_table', translations=name_map) # 指定数据库 models.UserInfo.objects.raw('select * from userinfo', using="default") ################### 原生SQL ################### from django.db import connection, connections cursor = connection.cursor() # cursor = connections['default'].cursor() cursor.execute("""SELECT * from auth_user where id = %s""", [1]) row = cursor.fetchone() # fetchall()/fetchmany(..) def values(self, *fields): # 获取每行数据为字典格式 def values_list(self, *fields, **kwargs): # 获取每行数据为元祖 def dates(self, field_name, kind, order='ASC'): # 根据时间进行某一部分进行去重查找并截取指定内容 # kind只能是:"year"(年), "month"(年-月), "day"(年-月-日) # order只能是:"ASC" "DESC" # 并获取转换后的时间 - year : 年-01-01 - month: 年-月-01 - day : 年-月-日 models.DatePlus.objects.dates('ctime','day','DESC') def datetimes(self, field_name, kind, order='ASC', tzinfo=None): # 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间 # kind只能是 "year", "month", "day", "hour", "minute", "second" # order只能是:"ASC" "DESC" # tzinfo时区对象 models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC) models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai')) """ pip3 install pytz import pytz pytz.all_timezones pytz.timezone(‘Asia/Shanghai’) """ def none(self): # 空QuerySet对象 #################################### # METHODS THAT DO DATABASE QUERIES # #################################### def aggregate(self, *args, **kwargs): # 聚合函数,获取字典类型聚合结果 from django.db.models import Count, Avg, Max, Min, Sum result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid')) ===> {'k': 3, 'n': 4} def count(self): # 获取个数 def get(self, *args, **kwargs): # 获取单个对象 def create(self, **kwargs): # 创建对象 def bulk_create(self, objs, batch_size=None): # 批量插入 # batch_size表示一次插入的个数 objs = [ models.DDD(name='r11'), models.DDD(name='r22') ] models.DDD.objects.bulk_create(objs, 10) def get_or_create(self, defaults=None, **kwargs): # 如果存在,则获取,否则,创建 # defaults 指定创建时,其他字段的值 obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2}) def update_or_create(self, defaults=None, **kwargs): # 如果存在,则更新,否则,创建 # defaults 指定创建时或更新时的其他字段 obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1}) def first(self): # 获取第一个 def last(self): # 获取最后一个 def in_bulk(self, id_list=None): # 根据主键ID进行查找 id_list = [11,21,31] models.DDD.objects.in_bulk(id_list) def delete(self): # 删除 def update(self, **kwargs): # 更新 def exists(self): # 是否有结果
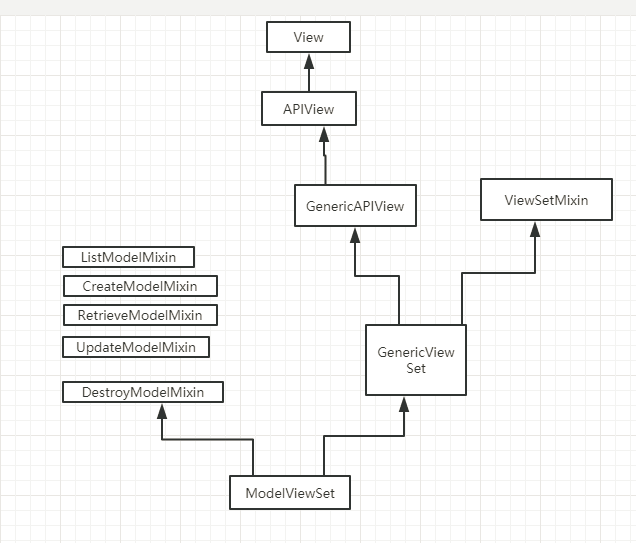
1)渲染器有坑 - 指定渲染器只用JSON - 视图: class UserView(...): queryset = [] # 必写 ... 2)assert 是的作用? 条件成立则继续往下,否则跑出异常,一般用于:满足某个条件之后,才能执行,否则应该跑出异常。 应用场景:rest framework class GenericAPIView(views.APIView): queryset = None serializer_class = None # If you want to use object lookups other than pk, set 'lookup_field'. # For more complex lookup requirements override `get_object()`. lookup_field = 'pk' lookup_url_kwarg = None # The filter backend classes to use for queryset filtering filter_backends = api_settings.DEFAULT_FILTER_BACKENDS # The style to use for queryset pagination. pagination_class = api_settings.DEFAULT_PAGINATION_CLASS def get_queryset(self): assert self.queryset is not None, ( "'%s' should either include a `queryset` attribute, " "or override the `get_queryset()` method." % self.__class__.__name__ ) queryset = self.queryset if isinstance(queryset, QuerySet): # Ensure queryset is re-evaluated on each request. queryset = queryset.all() return queryset 3) 用django写接口时,有没有用什么框架? - 使用rest framework框架 - 原生CBV 4) rest framework框架优点? rest framework帮助开发者提供了很多组件,可以提高开发效率。